.Net Core导入千万级数据至Mysql数据库的实现方法
发布时间:2021-06-25 16:32:17
最近在工作中,涉及到一个数据迁移功能,从一个txt文本文件导入到MySQL功能。
数据迁移,在互联网企业可以说经常碰到,而且涉及到千万级、亿级的数据量是很常见的。大数据量迁移,这里面就涉及到一个问题:高性能的插入数据。
今天我们就来谈谈MySQL怎么高性能插入千万级的数据。
我们一起对比以下几种实现方法:
前期准备
订单测试表
1 2 3 4 5 6 7 8 9 | CREATE TABLE `trade` (
`id` VARCHAR(50) NULL DEFAULT NULL COLLATE 'utf8_unicode_ci',
`trade_no` VARCHAR(50) NULL DEFAULT NULL COLLATE 'utf8_unicode_ci',
UNIQUE INDEX `id` (`id`),
INDEX `trade_no` (`trade_no`)
)
COMMENT='订单'
COLLATE='utf8_unicode_ci'
ENGINE=InnoDB;
|
测试环境
操作系统:Window 10 专业版
CPU:Inter(R) Core(TM) i7-8650U CPU @1.90GHZ 2.11 GHZ
内存:16G
MySQL版本:5.7.26
实现方法:
1、单条数据插入
这是最普通的方式,通过循环一条一条的导入数据,这个方式的缺点很明显就是每一次都需要连接一次数据库。
实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | var startTime = DateTime.Now;
using (var conn = new MySqlConnection(connsql))
{
conn.Open();
for (var i = 0; i < 100000; i++)
{
var sql = string.Format("insert into trade(id,trade_no) values('{0}','{1}');",
Guid.NewGuid().ToString(), "trade_" + (i + 1)
);
var sqlComm = new MySqlCommand();
sqlComm.Connection = conn;
sqlComm.CommandText = sql;
sqlComm.ExecuteNonQuery();
sqlComm.Dispose();
}
conn.Close();
}
var endTime = DateTime.Now;
var spanTime = endTime - startTime;
Console.WriteLine("循环插入方式耗时:" + spanTime.Minutes + "分" + spanTime.Seconds + "秒" + spanTime.Milliseconds + "毫秒");
|
10万条测试耗时:

上面的例子,我们是批量导入10万条数据,需要连接10万次数据库。我们把SQL语句改为1000条拼接为1条,这样就能减少数据库连接,实现代码修改如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | var startTime = DateTime.Now;
using (var conn = new MySqlConnection(connsql))
{
conn.Open();
var sql = new StringBuilder();
for (var i = 0; i < 100000; i++)
{
sql.AppendFormat("insert into trade(id,trade_no) values('{0}','{1}');",
Guid.NewGuid().ToString(), "trade_" + (i + 1)
);
if (i % 1000 == 999)
{
var sqlComm = new MySqlCommand();
sqlComm.Connection = conn;
sqlComm.CommandText = sql.ToString();
sqlComm.ExecuteNonQuery();
sqlComm.Dispose();
sql.Clear();
}
}
conn.Close();
}
var endTime = DateTime.Now;
var spanTime = endTime - startTime;
Console.WriteLine("循环插入方式耗时:" + spanTime.Minutes + "分" + spanTime.Seconds + "秒" + spanTime.Milliseconds + "毫秒");
|
10万条测试耗时:

通过优化后,原本需要10万次连接数据库,只需连接100次。从最终运行效果看,由于数据库是在同一台服务器,不涉及网络传输,性能提升不明显。
2、合并数据插入
在MySQL同样也支持,通过合并数据来实现批量数据导入。实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | var startTime = DateTime.Now;
using (var conn = new MySqlConnection(connsql))
{
conn.Open();
var sql = new StringBuilder();
for (var i = 0; i < 100000; i++)
{
if (i % 1000 == 0)
{
sql.Append("insert into trade(id,trade_no) values");
}
sql.AppendFormat("('{0}','{1}'),", Guid.NewGuid().ToString(), "trade_" + (i + 1));
if (i % 1000 == 999)
{
var sqlComm = new MySqlCommand();
sqlComm.Connection = conn;
sqlComm.CommandText = sql.ToString().TrimEnd(',');
sqlComm.ExecuteNonQuery();
sqlComm.Dispose();
sql.Clear();
}
}
conn.Close();
}
var endTime = DateTime.Now;
var spanTime = endTime - startTime;
Console.WriteLine("合并数据插入方式耗时:" + spanTime.Minutes + "分" + spanTime.Seconds + "秒" + spanTime.Milliseconds + "毫秒");
|
10万条测试耗时:

通过这种方式插入操作明显能够提高程序的插入效率。虽然第一种方法通过优化后,同样的可以减少数据库连接次数,但第二种方法:合并后日志量(MySQL的binlog和innodb的事务让日志)减少了,降低日志刷盘的数据量和频率,从而提高效率。同时也能减少SQL语句解析的次数,减少网络传输的IO。
3、MySqlBulkLoader插入
MySQLBulkLoader也称为LOAD DATA INFILE,它的原理是从文件读取数据。所以我们需要将我们的数据集保存到文件,然后再从文件里面读取。
实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | var startTime = DateTime.Now;
using (var conn = new MySqlConnection(connsql))
{
conn.Open();
var table = new DataTable();
table.Columns.Add("id", typeof(string));
table.Columns.Add("trade_no", typeof(string));
for (var i = 0; i < 100000; i++)
{
if (i % 500000 == 0)
{
table.Rows.Clear();
}
var row = table.NewRow();
row[0] = Guid.NewGuid().ToString();
row[1] = "trade_" + (i + 1);
table.Rows.Add(row);
if (i % 500000 != 499999 && i < (100000 - 1))
{
continue;
}
Console.WriteLine("开始插入:" + i);
var tradeCsv = DataTableToCsv(table);
var tradeFilePath = System.AppDomain.CurrentDomain.BaseDirectory + "trade.csv";
File.WriteAllText(tradeFilePath, tradeCsv);
#region 保存至数据库
var bulkCopy = new MySqlBulkLoader(conn)
{
FieldTerminator = ",",
FieldQuotationCharacter = '"',
EscapeCharacter = '"',
LineTerminator = "\r\n",
FileName = tradeFilePath,
NumberOfLinesToSkip = 0,
TableName = "trade"
};
bulkCopy.Columns.AddRange(table.Columns.Cast<DataColumn>().Select(colum => colum.ColumnName).ToList());
bulkCopy.Load();
#endregion
}
conn.Close();
}
var endTime = DateTime.Now;
var spanTime = endTime - startTime;
Console.WriteLine("MySqlBulk方式耗时:" + spanTime.Minutes + "分" + spanTime.Seconds + "秒" + spanTime.Milliseconds + "毫秒");
|
10万条测试耗时:

注意:MySQL数据库配置需开启:允许文件导入。配置如下:
secure_file_priv=
性能测试对比
针对上面三种方法,分别测试10万、20万、100万、1000万条数据记录,最终性能入如下:
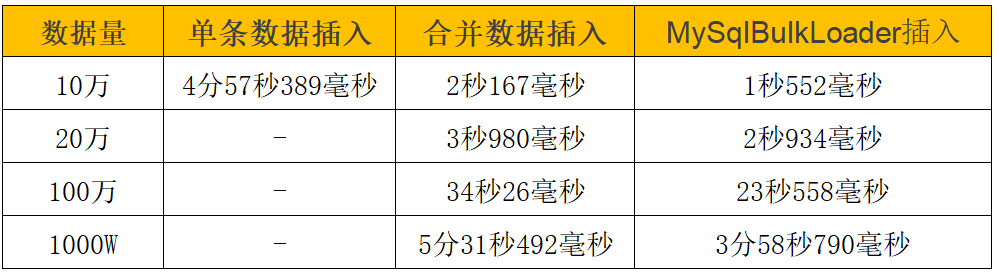
最后
通过测试数据看,随着数据量的增大,MySqlBulkLoader的方式表现依旧良好,其他方式性能下降比较明显。MySqlBulkLoader的方式完全可以满足我们的需求。